睡眠サプリって色々とあるけど飲むタイプは水を用意しないといけないから面倒。これは貼るだけだからズボラな自分でも続けられるし、スッと眠れるようになるから助かってる。

左記クレジットカード、銀行振込、コンビニ決済に対応
左記クレジットカード、銀行振込、コンビニ決済に対応




更新日:2025/4/14

| 個数 | 販売価格(1パッチあたり) | 販売価格(箱) | ポイント | 購入 |
|---|---|---|---|---|
| 30パッチ | 143円 | 4,300円 | 129pt | |
| 60パッチ | 130円 | 7,800円 | 234pt | |
| 90パッチ | 122円 | 11,000円 | 330pt |






①1万円以上で送料無料
1回の注文で10,000円以上だった場合、1,000円の送料が無料となります。
まとめ買いをすると1商品あたりのコストパフォーマンスが高くなるためおすすめです。
②プライバシー守る安心梱包
外箱に当サイト名や商品名が記載されることはないため、ご家族や配達員など第三者に内容を知られることは御座いません。

③100%メーカー正規品取り扱い
当サイトの商品は100%メーカー正規品となっており、第三者機関による鑑定も行っております。
商品の破損などがあった場合は再配送などにて対応させて頂きますので、ご連絡頂ければ幸いです。

④いつでも購入可能 処方箋不要
サイト上では24時間いつでもご注文を受けております。
また、お電話によるご注文も受け付けておりますのでネットが苦手な方はお気軽にどうぞ。

⑤商品到着100%
商品発送後はお荷物の追跡状況が分かる追跡番号をご案内させて頂きます。
郵便局には保管期限がありますのでご注意ください。
・自宅配達で不在だった場合の保管期限・・・16日間前後
・郵便局留めとした場合の保管期限・・・7~30日間

⑥コンビニ決済利用可能
ご近所のコンビニにていつでもお支払可能です。
セブンイレブンに限り店舗での機械操作を必要とせず、手続き完了後に表示されるバーコードや払込票番号をレジに提示することでお支払い頂けます。


不眠症の改善
25mgx200錠
7,200円

不眠症の改善
1mgx50錠
3,000円

不眠症の改善
10mgx100錠
4,590円

不眠症の改善
2mgx30錠
3,100円

不眠症の改善
8mgx100錠
34,600円

不眠症の改善
3mgx100錠
3,610円

不眠症の改善
2mgx50錠
4,110円

不安障害や不眠症の改善
5mgx200錠
5,400円

不眠症の改善
25mgx600錠
5,600円

睡眠の質を向上
60錠
4,460円

早漏の改善
10mlx1本
3,260円

早漏の改善
60mg3錠x1箱
12,160円

早漏の改善
2%30gx1本
5,360円
スリープスターター x 30パッチ
4,300円
ポイント:129pt
10,000円以上購入で送料無料
在庫あり

| 型 | 超短時間型 | 短時間型 | 中間型 | 長時間型 |
|---|---|---|---|---|
| 代表的な商品名 | ルネスタ | レンドルミン | ユーロジン | ドラール |
| 効果のピーク時間 | 1時間前後 | 1~3時間 | 1~3時間 | 3~5時間 |
| 効果時間 | 2~4時間 | 6~10時間 | 20~24時間 | 24時間以上 |
| 向いている人 | 寝付きが悪い | 寝付きが悪い 夜中に何度も目が 覚める | 夜中に何度も 目が覚める | 予定よりも早く 目が覚める |
睡眠サプリって色々とあるけど飲むタイプは水を用意しないといけないから面倒。これは貼るだけだからズボラな自分でも続けられるし、スッと眠れるようになるから助かってる。
私には飲み薬の方が効き目があるように感じました。結構重い不眠症には効かないのかもです。
| 1日の使用回数 | 1回 |
|---|---|
| 1回の使用量 | 1枚 |
| 使用のタイミング | 就寝前 |
| 使用間隔 | 指定なし |
| 商品名 | フルナイト | ハイプロン | ハイプナイト | ソクナイト | アモバン・ジェネリック | エスゾピック | ソミナー | ロゼレム |
|---|---|---|---|---|---|---|---|---|
| 商品画像 | | | |  |  | | | |
| 特徴1 | ・依存性の心配が少なく安全性が高い | ・素早い効果が期待できる超短時間型 | ・長期連用において効果の減弱がみられにくい | ・脳の活動を抑制して眠気をあらわす | ・睡眠薬の中でも副作用のリスクが少ない | ・ジェネリック医薬品なので経済的 | ・入眠障害や中途覚醒を改善できる | ・自然に近い作用で催眠効果を発揮する |
| 特徴2 | ・長期連用しても効果の減弱がみられにくい | ・眠気に関わる部分だけに作用して効果を発揮 | ・依存性の心配が少なく、安全性が高い | ・転倒やふらつきなどの副作用が起きにくい | ・早く効いて効果が翌朝に残らない | ・睡眠薬が初めての方にも使いやすい | ・アレルギー症状に対する効果も期待できる | ・緩やかな効果で不眠症を改善する |
| 内容量 | 2mgx50錠 | 10mgx100錠 | 1mgx50錠 | 2mg50錠x1箱 | 7.5mgx30錠 | 2mgx30錠 | 25mgx200錠 | 8mgx100錠 |
| 価格 | 4,110円 | 4,590円 | 3,000円 | 4,110円 | 2,400円 | 3,100円 | 7,200円 | 34,600円 |
本製品は海外製のため、期限表記が日本と異なる場合がございます。
パッケージ裏面や側面、シートなどに以下のような表記がされています。
| EXP | 使用期限 例:EXP 12/2025→2025年12月まで使用可 |
|---|---|
| MFG または MFD | 製造日 例:MFG 03/2023 |
| BEST BEFORE | 品質が最も安定している目安日 |
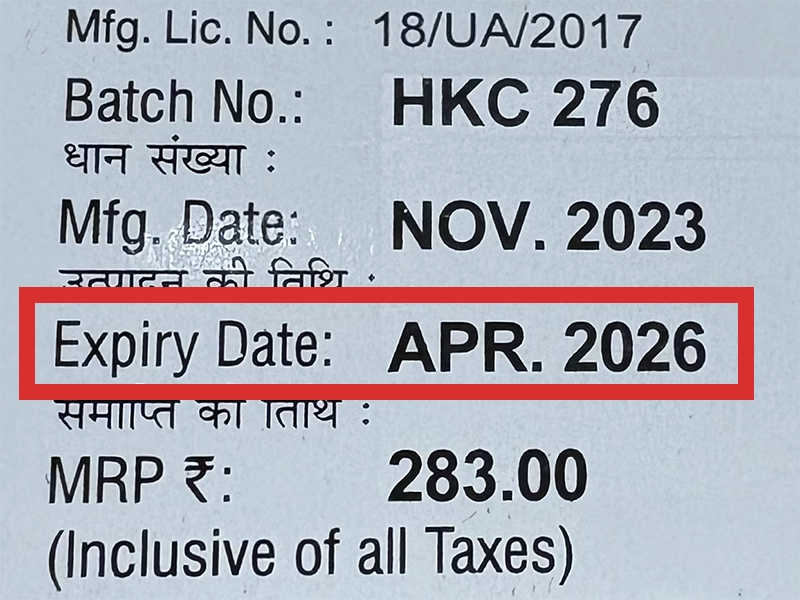
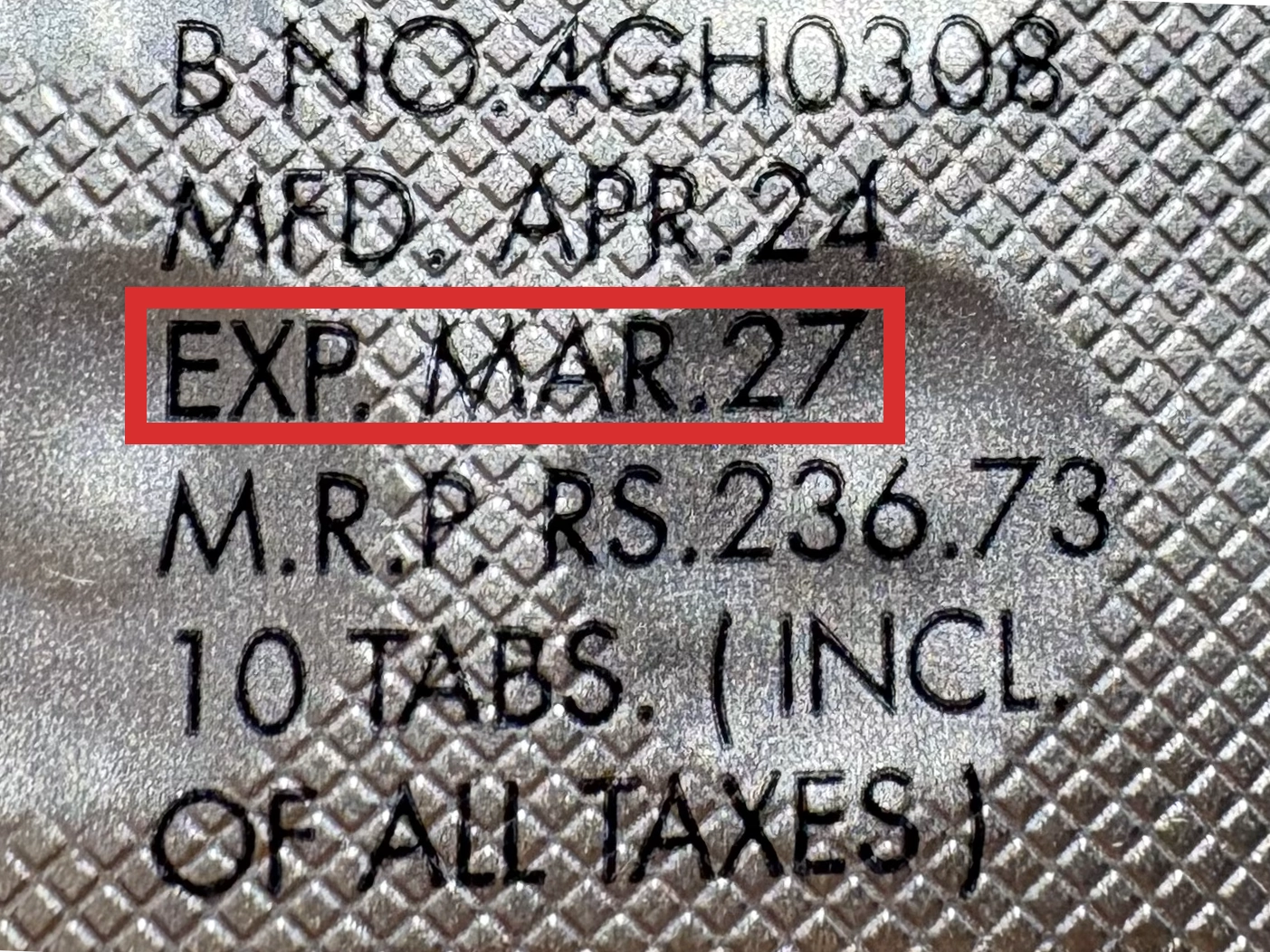
※国や製品により日付の並び(例:月/年、日/月/年)が異なる場合がありますのでご注意ください
EXP(Expiry Date) の表記がなく、MFG または MFDしか記載がないケースがあります。
この場合は MFG(MFD) から2~3年が使用期限の目安です。
※「LOT」や「BATCH」の表記は製造番号であり期限ではありません。

パッケージ例となります。
商品やご注文単位によってはシート単位でのお届けとなる場合が御座います。
外箱に当サイト名や商品名が記載されることはないため、ご家族や配達員など第三者に内容を知られることは御座いません。
睡眠サプリって色々とあるけど飲むタイプは水を用意しないといけないから面倒。これは貼るだけだからズボラな自分でも続けられるし、スッと眠れるようになるから助かってる。
貼るタイプの睡眠サプリが気になったので買ってみました!最初は効いているのかわかりませんでしたが、最近は寝付くスピードが早くなってきています^^思いのほか効き目がいいので気に入りました。
いきなり睡眠薬を飲むのはハードルが高かったからこれにしたけど私には微妙。他のサプリメントも試してみようかな。
じんわりと眠気がきて眠ってしまう、という感じです。貼ってから時間をあけてベッドに入ると効き目はあまり感じられないので、私は寝る直前に貼るようにしています。
貼るタイプは見たことが無かったので気になったのと、薬を飲むのは抵抗があったので購入しました。届くまで少し時間がかかるみたいでまだ手元にはありませんが効果があれば良いなと思います。
商品口コミの投稿は会員のみ行えるようになっております。
お手数ですが会員ログインの上でご投稿頂きますようお願いいたします。
口コミをご投稿頂いたお客様にはポイントをプレゼントさせて頂いております。
文章のみであれば100ポイント、文章+写真付きのものは300ポイントをプレゼントさせて頂きます。
規約や詳細などはこちらをご確認くださいませ。