










助けられている薬です。初めは効いているのかわからず服用を続けていました。ですが、続けているうちに落ち込みやすく、憂鬱だった気持ちが薄れていきました。とても生活が送りやすくなったので、レクサプロに出会えて本当に良かったです。

左記クレジットカード、銀行振込、コンビニ決済に対応
左記クレジットカード、銀行振込、コンビニ決済に対応



更新日:2025/6/8
| 商品名 | パキシル・ジェネリック | ファベリン | フルニル | サインバルタ・ジェネリック | キセパール | セルタファイン | インシドン | イフェクサーXR |
|---|---|---|---|---|---|---|---|---|
| 商品画像 |  |  |  |  |  |  |  |  |
| 特徴1 | ・症状に応じて4種類から選べる | ・抗うつ薬特有の副作用が少ない | 世界が認めた抗うつ成分を配合 | 先発薬サインバルタよりも安価に購入可 | ・優れた効果で精神症状を改善できる | ・憂うつな気分や不安感をやわらげる | ・神経伝達物質のバランスを整える | ・副作用の心配が少ない第4世代の抗うつ薬 |
| 特徴2 | ・パキシルのジェネリックで安価 | ・根本的な部分からうつ症状を改善できる | 有効成分はパニック障害にも有用とされる | 初めての服用に適した20mg錠あり | ・セロトニン系の神経にのみ作用するのが特徴 | ・従来の抗うつ薬と比べて、口渇や便秘などの副作用が軽減されている | ・古くから使用される三環系抗うつ剤 | ・不安による不眠症にも効果が期待できる |
| 内容量 | 10mgx100錠 | 100mgx30錠 | 10mgx100錠 | 20mgx100錠 | 40mg50錠x1箱 | 100mg100錠x1箱 | 50mg100錠x1箱 | 75mgx28錠 |
| 価格 | 9,460円 | 4,860円 | 3,560円 | 6,060円 | 8,060円 | 6,260円 | 9,160円 | 6,060円 |
レクサプロは、日本国内でも心療内科などで処方されることがある抗うつ剤です。
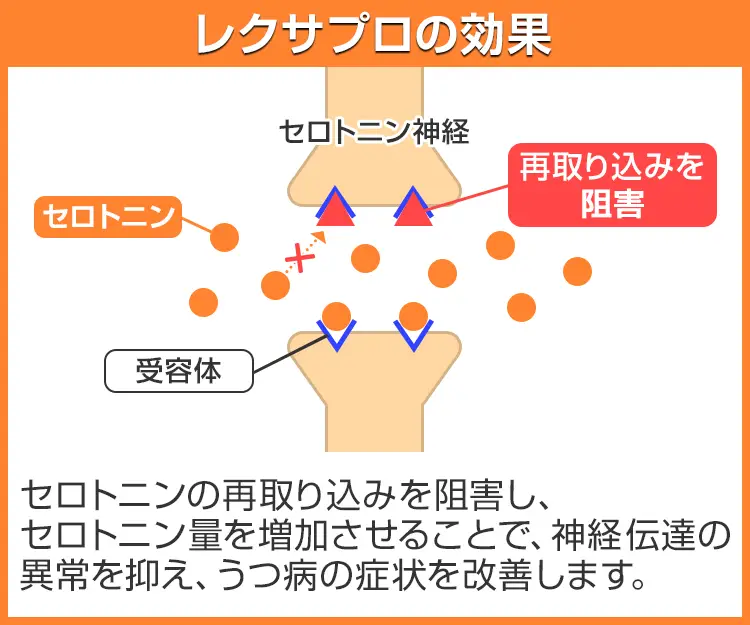
複数あるSSRI(選択的セロトニン再取り込み阻害薬)の中でも、比較的早く効果があらわれる傾向にあると報告されています。
| メーカー | ルンドベック(Lundbeck) |
|---|---|
| 有効成分 | エスシタロプラムシュウ酸塩 |
| 効果 | うつ症状の改善(MDD・GAD) |
| 副作用 | 吐き気や不眠など |
| 用法 | 1日1回、夕食後に服用 |
レクサプロには、有効成分としてエスシタロプラムが含有されています。脳内において、いったん放出されたセロトニン(心を落ち着かせる神経伝達物質)の再取り込みを防ぎ、濃度を高めることで抑うつ症状を改善させる作用があります。
レクサプロは1錠あたりエスシタロプラムを20mg含有しています。

| 個数 | 販売価格(1錠あたり) | 販売価格(箱) | ポイント | 購入 |
|---|---|---|---|---|
| 28錠 | 355円 | 9,960円 | 298pt | 売り切れ |






①1万円以上で送料無料
1回の注文で10,000円以上だった場合、1,000円の送料が無料となります。
まとめ買いをすると1商品あたりのコストパフォーマンスが高くなるためおすすめです。
②プライバシー守る安心梱包
外箱に当サイト名や商品名が記載されることはないため、ご家族や配達員など第三者に内容を知られることは御座いません。

③100%メーカー正規品取り扱い
当サイトの商品は100%メーカー正規品となっており、第三者機関による鑑定も行っております。
商品の破損などがあった場合は再配送などにて対応させて頂きますので、ご連絡頂ければ幸いです。

④いつでも購入可能 処方箋不要
サイト上では24時間いつでもご注文を受けております。
また、お電話によるご注文も受け付けておりますのでネットが苦手な方はお気軽にどうぞ。

⑤商品到着100%
商品発送後はお荷物の追跡状況が分かる追跡番号をご案内させて頂きます。
郵便局には保管期限がありますのでご注意ください。
・自宅配達で不在だった場合の保管期限・・・16日間前後
・郵便局留めとした場合の保管期限・・・7~30日間

⑥コンビニ決済利用可能
ご近所のコンビニにていつでもお支払可能です。
セブンイレブンに限り店舗での機械操作を必要とせず、手続き完了後に表示されるバーコードや払込票番号をレジに提示することでお支払い頂けます。

レクサプロ 20mg x 28錠
9,960円
ポイント:298pt
10,000円以上購入で送料無料
売り切れ

助けられている薬です。初めは効いているのかわからず服用を続けていました。ですが、続けているうちに落ち込みやすく、憂鬱だった気持ちが薄れていきました。とても生活が送りやすくなったので、レクサプロに出会えて本当に良かったです。
吐き気が凄い。怖くてもう飲めない。
レクサプロは、うつ病による気分の重さや無気力感に対して効果がある薬です。国内外の臨床試験でプラセボに比べて有意に症状が改善されたことが報告されており、特に気分の回復や生活意欲の向上が期待できます。
レクサプロは社会不安障害(社交不安障害)にも効果がある薬です。国内臨床試験では、人前に出る場面での不安感が軽減されたことが確認されています。継続的な服用で緊張しやすい場面でも落ち着きやすくなる方が多いです。
服用を開始してから1~2週間ほどで効果の兆しが見られ始め、4~8週でしっかりした効果を感じる方が多いです。個人差がありますが、継続が重要なので途中でやめないことが大切です。
長期投与でもレクサプロの効果は持続すると報告されています。52週間の臨床試験では気分の改善が維持され、再発も防がれたという結果が得られています。慢性的なうつ症状にも対応できます。
1日1回、夕食後に服用するのが基本です。これは副作用で眠気などの症状があらわれる可能性があるためです。ですから、レクサプロは朝ではなく夜に服用するようにしてください。
飲み忘れに気づいた時点ですぐに気づけばその日のうちに服用します。ただし、次の服用時間が近い場合は1回分を飛ばして通常どおりに戻します。2回分を一度に飲むのは避けましょう。
急にやめると、めまいや不安感などの離脱症状が出ることがあります。そのため、レクサプロの服用をやめるときは少しずつ量を減らしていくのが基本となっています。どの程度減らしていくのかといったことについては、医師と相談しながら進める必要があります。
レクサプロは、毎日決まった時間に1回飲むことで血中濃度が安定しやすく、効果も持続しやすくなります。飲む時間は夕食後と指定されているため、できるだけ一定に保つようにしましょう。
飲み始めに一時的に気分が不安定になったり、落ち込みが強くなることがあります。うつ病の患者さんでは、特に初期に自殺念慮が現れる可能性があるため、状態の変化には十分な注意が必要です。
一部の薬とは併用できません。たとえばピモジドやMAO阻害剤などと一緒に飲むと、心臓や脳に重い副作用を起こすおそれがあるため、併用は避ける必要があります。飲んでいる薬がある場合は、事前に併用しても問題がないか確認しましょう。
高齢者は薬が体に長く残りやすく、副作用も出やすい傾向があります。眠気やふらつき、電解質異常などが起こることがあるため、年齢に応じた量の調整や慎重な経過観察が必要です。
主な副作用には眠気や吐き気、頭痛や口の渇きなどがあります。特に治療初期や量の変更時に出やすい傾向があり、多くは軽度ですが、症状が気になる場合は相談が必要です。
| 1日の服用回数 | 1回 |
|---|---|
| 1日の服用量 | 10mg |
| 服用のタイミング | 夕食後 |
| 服用間隔 | 24時間 |
| 5%以上 | 1〜5%未満 | 1%未満 | 頻度不明 | |
| 全身症状 | 倦怠感 | 異常感 | 無力症、浮腫、熱感、発熱、悪寒、疲労、体重増加、体重減少 | |
| 過敏症 | 発疹、湿疹、蕁麻疹、そう痒 | アナフィラキシー反応、血管浮腫 | ||
| 精神神経系 | 傾眠(22.6%)、浮動性めまい、頭痛 | あくび、不眠症、体位性めまい、感覚鈍麻、易刺激性(いらいら感、焦燥) | アカシジア、睡眠障害、異常夢(悪夢を含む)、激越、不安、錯乱状態、躁病、落ち着きのなさ、錯感覚(ピリピリ感等)、振戦、リビドー減退、歯ぎしり | パニック発作、精神運動不穏、失神、幻覚、神経過敏、離人症、ジスキネジー、運動障害、無オルガズム症 |
| 消化器 | 悪心(20.7%)、口渇 | 腹部不快感、下痢、食欲減退、腹痛、嘔吐、便秘 | 腹部膨満、胃炎、食欲亢進、消化不良 | |
| 循環器 | 動悸 | 起立性低血圧、QT延長 | 頻脈、徐脈 | |
| 血液 | 赤血球減少、ヘマトクリット減少、ヘモグロビン減少、白血球増加、血小板増加、血小板減少、鼻出血 | 出血傾向(斑状出血、消化管出血等) | ||
| 肝臓 | AST・ALT・Al-P・γ-GTP・ビリルビンの上昇等の肝機能検査値異常 | 肝炎 | ||
| 筋骨格系 | 関節痛、筋肉痛、肩こり、こわばり | |||
| 泌尿器・生殖器 | 排尿困難、尿蛋白陽性、射精障害 | 頻尿、尿閉、不正出血、勃起不全、射精遅延 | 持続勃起症、月経過多 | |
| その他 | 回転性めまい、耳鳴、多汗症 | 副鼻腔炎、味覚異常、脱毛、コレステロール上昇、血中ナトリウム低下、乳汁漏出、胸部不快感、寝汗、羞明、霧視、過換気、尿糖陽性 | 視覚異常、散瞳、高プロラクチン血症 |
本製品は海外製のため、期限表記が日本と異なる場合がございます。
パッケージ裏面や側面、シートなどに以下のような表記がされています。
| EXP | 使用期限 例:EXP 12/2025→2025年12月まで使用可 |
|---|---|
| MFG または MFD | 製造日 例:MFG 03/2023 |
| BEST BEFORE | 品質が最も安定している目安日 |
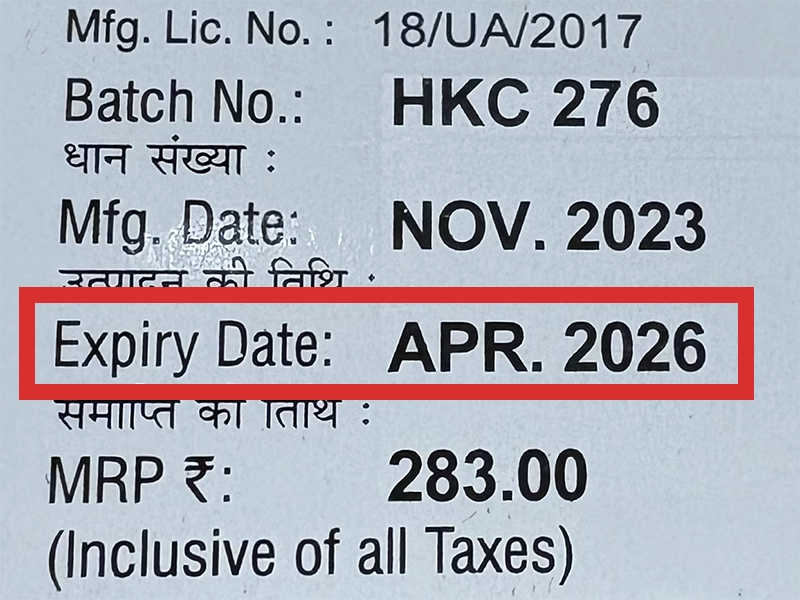
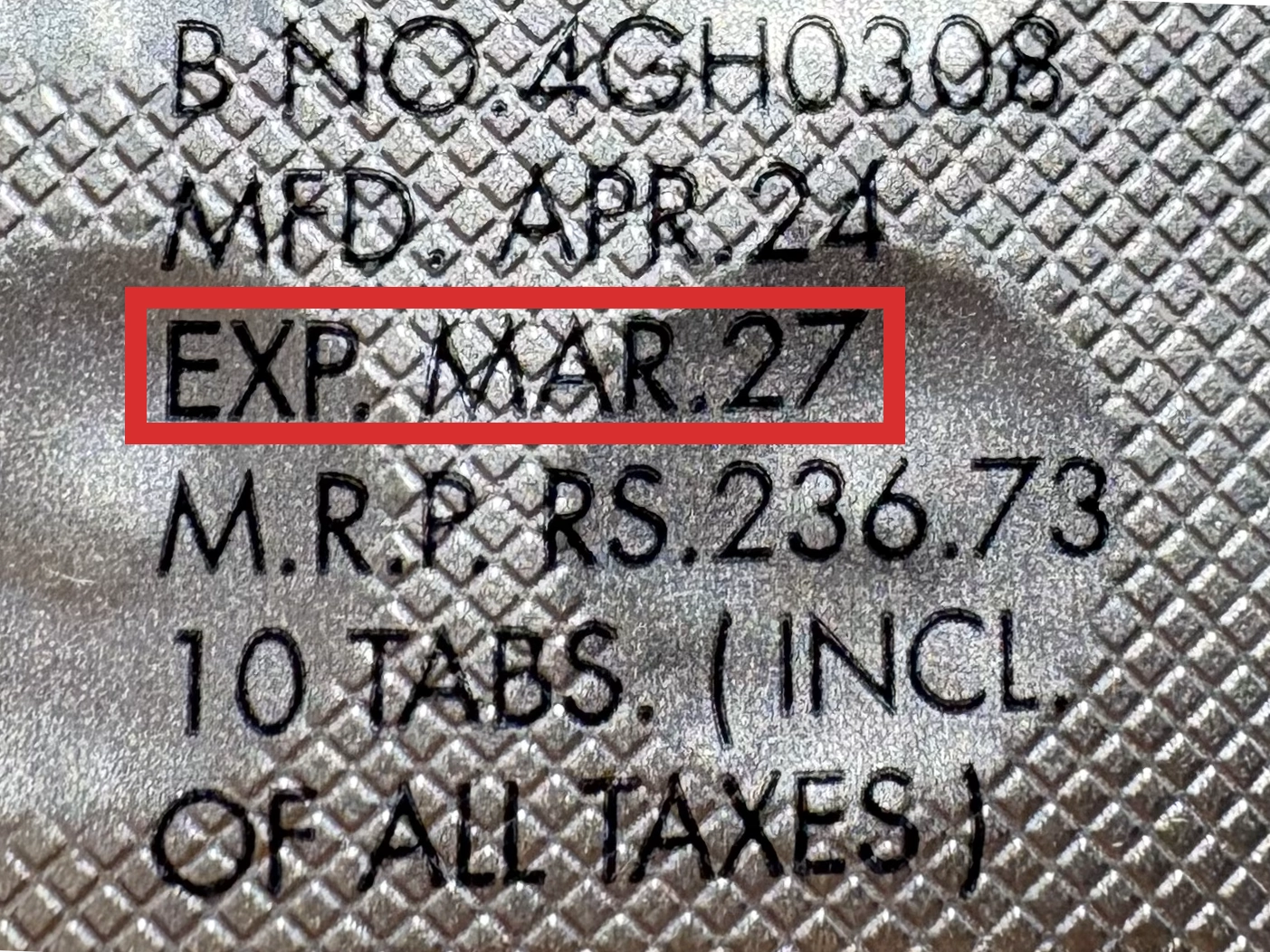
※国や製品により日付の並び(例:月/年、日/月/年)が異なる場合がありますのでご注意ください
EXP(Expiry Date) の表記がなく、MFG または MFDしか記載がないケースがあります。
この場合は MFG(MFD) から2~3年が使用期限の目安です。
※「LOT」や「BATCH」の表記は製造番号であり期限ではありません。

パッケージ例となります。
商品やご注文単位によってはシート単位でのお届けとなる場合が御座います。
外箱に当サイト名や商品名が記載されることはないため、ご家族や配達員など第三者に内容を知られることは御座いません。
助けられている薬です。初めは効いているのかわからず服用を続けていました。ですが、続けているうちに落ち込みやすく、憂鬱だった気持ちが薄れていきました。とても生活が送りやすくなったので、レクサプロに出会えて本当に良かったです。
初めて服用した時は口の乾きが気になりました。今は慣れてしまったのでの服用は続けています。レクサプロを飲むと気持ちが安心するので、薬はちゃんと効いているようです。
自分的にはうつじゃないかな。と思ったので買ってみました。意外と副作用を感じますね。少し我慢して、どれだけ改善されるか見てみます。
吐き気が凄い。怖くてもう飲めない。
夜になると不安になるので眠れなくなっていたのですが、レクサプロは不安な気持ちを落ち着けてくれるので気持ち穏やかに眠れることが出来ます。
商品口コミの投稿は会員のみ行えるようになっております。
お手数ですが会員ログインの上でご投稿頂きますようお願いいたします。
口コミをご投稿頂いたお客様にはポイントをプレゼントさせて頂いております。
文章のみであれば100ポイント、文章+写真付きのものは300ポイントをプレゼントさせて頂きます。
規約や詳細などはこちらをご確認くださいませ。