マツエクしてたときと同じくらいのフサフサ感。ドラッグストアでまつ毛育毛剤買ってる人は、絶対ルミガンを買うべきです。

左記クレジットカード、銀行振込、コンビニ決済に対応
左記クレジットカード、銀行振込、コンビニ決済に対応




更新日:2025/4/26
| 有効成分 | ビマトプロスト | |||
|---|---|---|---|---|
| メーカー | Allergan | 内容量 | 3ml(0.01%)x1箱 | |
| 発送国 | 香港・インド・シンガポール・タイ | 効果 | まつ毛の育毛 | |
| 副作用 | 結膜充血や眼そう痒症など | 用法 | 1日1回、就寝前にまつ毛へ塗布 | |

| 個数 | 販売価格(1箱あたり) | 販売価格(箱) | ポイント | 購入 |
|---|---|---|---|---|
| 1箱 | 5,960円 | 5,960円 | 178pt | |
| 3箱 | 4,753円 | 14,260円 | 427pt | |
| 5箱 | 3,912円 | 19,560円 | 586pt |
| 個数 | 販売価格(1箱あたり) | 販売価格(箱) | ポイント | 購入 |
|---|---|---|---|---|
| 1箱 | 6,560円 | 6,560円 | 196pt | |
| 3箱 | 5,186円 | 15,560円 | 466pt | |
| 5箱 | 4,412円 | 22,060円 | 661pt |






①1万円以上で送料無料
1回の注文で10,000円以上だった場合、1,000円の送料が無料となります。
まとめ買いをすると1商品あたりのコストパフォーマンスが高くなるためおすすめです。
②プライバシー守る安心梱包
外箱に当サイト名や商品名が記載されることはないため、ご家族や配達員など第三者に内容を知られることは御座いません。

③100%メーカー正規品取り扱い
当サイトの商品は100%メーカー正規品となっており、第三者機関による鑑定も行っております。
商品の破損などがあった場合は再配送などにて対応させて頂きますので、ご連絡頂ければ幸いです。

④いつでも購入可能 処方箋不要
サイト上では24時間いつでもご注文を受けております。
また、お電話によるご注文も受け付けておりますのでネットが苦手な方はお気軽にどうぞ。

⑤商品到着100%
商品発送後はお荷物の追跡状況が分かる追跡番号をご案内させて頂きます。
郵便局には保管期限がありますのでご注意ください。
・自宅配達で不在だった場合の保管期限・・・16日間前後
・郵便局留めとした場合の保管期限・・・7~30日間

⑥コンビニ決済利用可能
ご近所のコンビニにていつでもお支払可能です。
セブンイレブンに限り店舗での機械操作を必要とせず、手続き完了後に表示されるバーコードや払込票番号をレジに提示することでお支払い頂けます。


まつ毛の育毛
3ml(0.03%)x1箱
3,560円

まつ毛の育毛
3ml(0.03%)x1本
3,060円

まつ毛の育毛
3ml(0.03%)x1セット
5,460円

まつ毛の育毛
3ml(0.03%)x1セット
4,160円

まつ毛の育毛
3.5mlx1本
19,660円

まつ毛の育毛
3mlx1本
4,360円

まつ毛育毛
5mlx1本
3,860円

避妊や生理不順などの改善
20錠x1箱
1,700円

鎮痛や消炎
250mg/150mlx1本
4,860円

白内障の改善や予防
10mlx1本
2,960円

早漏の改善
10mlx1本
3,260円

早漏の改善
60mg3錠x1箱
12,160円

早漏の改善
2%30gx1本
5,360円

慢性副腎機能不全などの改善
5mgx60錠
4,360円

結膜炎や角膜炎などの改善
5mlx1本
3,860円
ルミガン 3ml(0.01%) x 1箱
5,960円
ポイント:178pt
10,000円以上購入で送料無料
在庫あり

マツエクしてたときと同じくらいのフサフサ感。ドラッグストアでまつ毛育毛剤買ってる人は、絶対ルミガンを買うべきです。
しょぼい私のまつ毛を改善するために毎日頑張って塗っていたら、まつ毛の際が黒くなってきました(´;ω;`)こんなにも色素沈着するなんて思ってもいなかった…一旦塗るのをやめて色素沈着が落ち着いてきたら、また塗ろうかな…
まつ毛の成長を促す効果があります。まつ毛の長さを伸ばすだけでなく、太さを増し、色を濃くする効果にも期待できるため、まつ毛が少ない方や細い方、薄いと感じる方に使われています。
毎日使用した場合、4週間ほどでまつ毛の成長が始まります。その後、2〜4か月の使用ではっきりとした効果を実感できることが多いとされています。効果が出るまでには個人差がありますが、焦らず続けることがポイントです。
はい、ビマトプロストはまつ毛の色素を濃くする働きがあるため、使い続けることでまつ毛の色が濃く、しっかりした印象になります。ただし、変化には個人差があり、効果のあらわれ方も異なります。
使用をやめると時間の経過とともに、まつ毛は元の状態へと戻ってしまいます。まつ毛の成長効果を維持するには、継続的な使用が必要とされています。
夜にメイクを落として、顔を洗ったあとまつ毛の生え際に専用のアプリケーターで1日1回だけ塗布します。塗りすぎると刺激の原因になるため、決められた量を守り、上まつ毛だけに使用するのが基本です。
ビマトプロストは下まつ毛には使用しないことが推奨されています。下まぶたに使うと薬が広がりやすく、思わぬ副作用(色素沈着など)が起きる可能性があるため、上まつ毛の生え際だけに塗るようにしましょう。
ビマトプロストを塗った後は、薬剤が十分に浸透するまで洗顔や目元を濡らすことは避けた方がよいです。少なくとも数時間は洗顔や水に濡らさないようにし、夜間に使用した後は、そのまま眠ることが推奨されています。
塗布前には必ずメイクを落とし、顔とまつ毛を清潔な状態にしておく必要があります。まつ毛が汚れたままだと薬の効果が弱まったり、目の周囲に刺激を感じる原因になるため、丁寧な洗顔が重要です。
目の周囲に色素沈着が起こる可能性があるため、まつ毛以外に薬が広がらないように注意して使う必要があります。また、塗布後は清潔なティッシュなどで目元を軽くふき取ると、副作用を防ぎやすくなります。
まつ毛の生え際のかゆみや赤み、色素沈着が比較的よくみられる副作用です。症状が軽い場合は自然におさまることもありますが、変化が続く場合は使用を中止するか、方法を見直すことが必要になることもあります。
まぶたの皮膚に色素沈着が起きた場合は、塗布量を見直したり、塗り方を改善するだけで自然に薄くなることがあります。無理にこすったりせず、丁寧なスキンケアを続けることが大切です。
緑内障の治療に用いられる点眼薬との併用には注意が必要となっています。ルミガンの有効成分も緑内障の治療に用いられることがあるため、併用で効果が重複してしまい副作用のリスクが高まってしまうためです。
| 1日の使用回数 | 1回 |
|---|---|
| 1回の使用量 | 1滴 |
| 使用のタイミング | 就寝前 |
| 使用間隔 | 毎日 |
| 1日の使用回数 | 1回 |
|---|---|
| 1回の使用量 | 1滴 |
| 使用のタイミング | 就寝前 |
| 使用間隔 | 指定なし |
| 商品名 | ケアプロスト+アプリケーター80本セット | ルミガン+アプリケーター60本セット | ビマトアイドロップ | ケアプロスト | ルミガン専用アプリケーター | モデルアイズ・モデラッシュ | ヒマラヤアイライナーカジャル | ケアプロストプラス | リバイタラッシュ |
|---|---|---|---|---|---|---|---|---|---|
| 商品画像 | | | | |  | |  | | |
| 特徴1 | ・日本国内でも認可されている成分を配合 | ・日本国内で唯一認可されたまつ毛美容液 | ・20年以上の実績がある成分を配合 | ・ルミガンと変わらない効果を期待できる | ・ルミガンを簡単に塗布できるアプリケーター | ・手軽にまつ毛の成長を促進できる | ・100%天然成分で作られたアイライナー | ・緑内障や高眼圧症の対策にも効果的 | ・まつ毛に保湿力と柔軟性を与える効果もある |
| 特徴2 | ・専用のアプリケーターで清潔に使用できる | ・はじめての人も使いやすいセット製品 | ・ルミガンと同じ効果を期待することができる | ・海外で古くから注目されていた成分を使用 | ・何度も購入し直す手間を省きながら使用可能 | ・1本で約70日間使用することが可能 | ・敏感肌の方でも安心して使用できる | ・使用開始から約8週間で効果を実感できる | ・まつ毛の貧毛や脱毛などの症状に効果的 |
| 内容量 | 3ml(0.03%)x1セット | 3ml(0.03%)x1セット | 3ml(0.03%)x1本 | 3ml(0.03%)x1箱 | 40本 | 5mlx1本 | 1GRAMx1本 | 3mlx1本 | 3.5mlx1本 |
| 価格 | 4,160円 | 5,460円 | 3,060円 | 3,560円 | 1,200円 | 3,860円 | 2,660円 | 4,360円 | 19,660円 |
| 5%以上 | 1〜5%未満 | 0.1〜1%未満 | 頻度不明 | |
| 眼 | 睫毛の異常(睫毛が長く、太く、濃くなる等)(52.8%)、結膜充血(44.9%)、眼瞼色素沈着(20.5%)、眼そう痒症(9.6%)、眼瞼の多毛症 | 結膜炎、結膜浮腫、結膜出血、眼瞼浮腫、眼瞼紅斑、眼瞼そう痒症、眼瞼障害、眼脂、点状角膜炎、角膜びらん、眼刺激、霧視、眼の異常感(違和感、べとつき感等)、くぼんだ眼 | 結膜色素沈着、眼瞼炎、眼瞼下垂、霰粒腫、マイボーム腺梗塞、糸状角膜炎、角膜血管新生、虹彩炎、眼乾燥、眼の灼熱感、眼痛、羞明、白内障、眼精疲労、視力低下、視覚障害、眼球運動失調、眼圧上昇 | ぶどう膜炎、黄斑浮腫、乾性角結膜炎、流涙、涙液分泌低下 |
| 循環器 | 狭心症発作、高血圧 | |||
| 消化器 | 胃不快感 | |||
| 呼吸器 | 咳嗽 | |||
| その他 | 尿潜血、CK増加 | 口唇疱疹、浮動性めまい、頭痛、胸痛、耳鳴、白血球数増加、ALT(GPT)増加、γ−GTP増加 |
本製品は海外製のため、期限表記が日本と異なる場合がございます。
パッケージ裏面や側面、シートなどに以下のような表記がされています。
| EXP | 使用期限 例:EXP 12/2025→2025年12月まで使用可 |
|---|---|
| MFG または MFD | 製造日 例:MFG 03/2023 |
| BEST BEFORE | 品質が最も安定している目安日 |
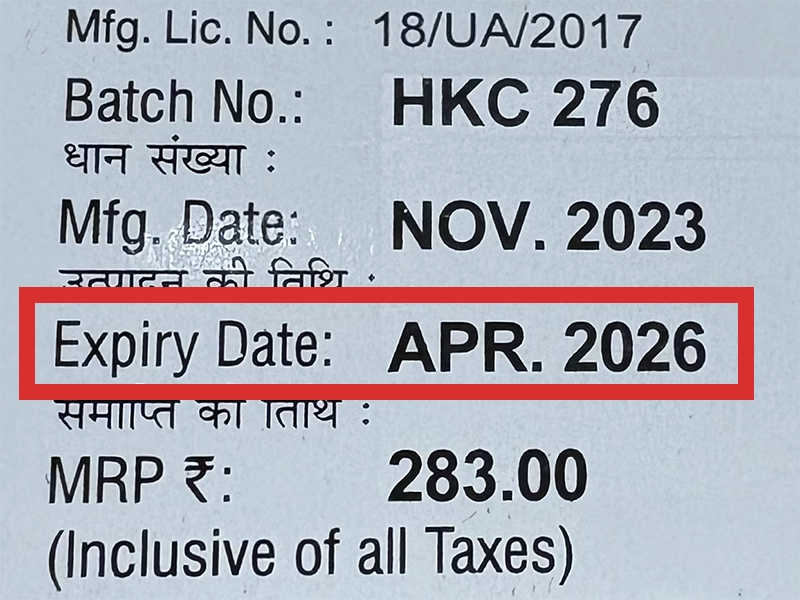
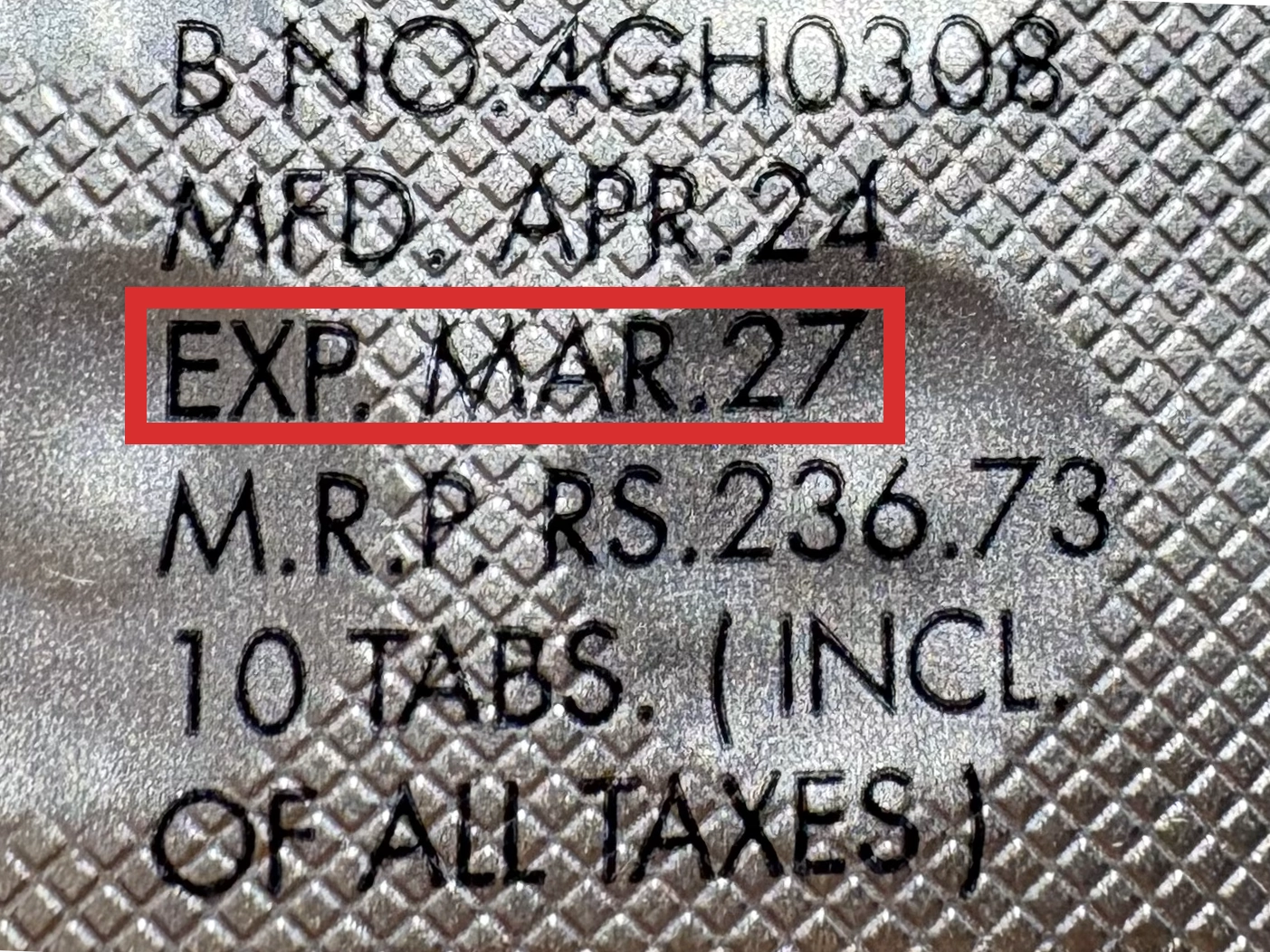
※国や製品により日付の並び(例:月/年、日/月/年)が異なる場合がありますのでご注意ください
EXP(Expiry Date) の表記がなく、MFG または MFDしか記載がないケースがあります。
この場合は MFG(MFD) から2~3年が使用期限の目安です。
※「LOT」や「BATCH」の表記は製造番号であり期限ではありません。

パッケージ例となります。
商品やご注文単位によってはシート単位でのお届けとなる場合が御座います。
外箱に当サイト名や商品名が記載されることはないため、ご家族や配達員など第三者に内容を知られることは御座いません。
マツエクしてたときと同じくらいのフサフサ感。ドラッグストアでまつ毛育毛剤買ってる人は、絶対ルミガンを買うべきです。
本当に驚き!期待以上の効果です!会う人みんなにまつ毛が長くて羨ましいと言われます!これは間違いなく私的ヒット商品です。リピはもちろん、買い占めたいくらいです(笑)
口コミが良いので買ってみたものの、まだ使い始めて3日だからなのか何の変化も感じられません。。。はやくまつ毛長くなってほしい
以前はまつエクだったんだけどお金も時間もかかるので友人からオススメしてもらっていたルミガンを使ってみたところビックリ。伸びるだけじゃなくて太くなっていてまつ毛が育っている感がすごいです。ありがとう!
40代のまつ毛でもしっかりと育ちます。このお値段でこれだけの効果があるとは思ってもいませんでした。使い始めた1週間後には3本をまとめ買いしました?
商品口コミの投稿は会員のみ行えるようになっております。
お手数ですが会員ログインの上でご投稿頂きますようお願いいたします。
口コミをご投稿頂いたお客様にはポイントをプレゼントさせて頂いております。
文章のみであれば100ポイント、文章+写真付きのものは300ポイントをプレゼントさせて頂きます。
規約や詳細などはこちらをご確認くださいませ。